
Debugging PDF files
Categories: Development, PDF
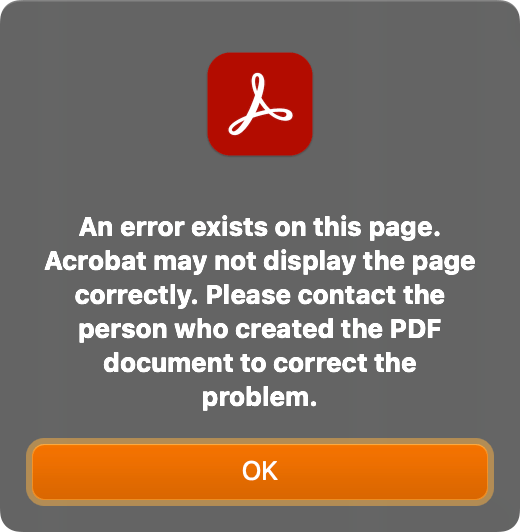
While developing the speedata Publisher, I have to create PDF instructions to draw shapes, create accessibility data structures and embed files for example. For boxes and glue, I have to create a PDF file from scratch. But once in a while I make mistakes and the PDF file cannot be displayed in the viewer. Then I need to look into the PDF file and check manually where the problem is. For example Adobe Acrobat shows a message:
Binary or not binary
What kind of PDF file format is PDF? Is it a binary or a text file format? I’d say it is both. Normally PDF files are compressed, and the text editors or text viewers like “less” do not show the file or show garbled data.
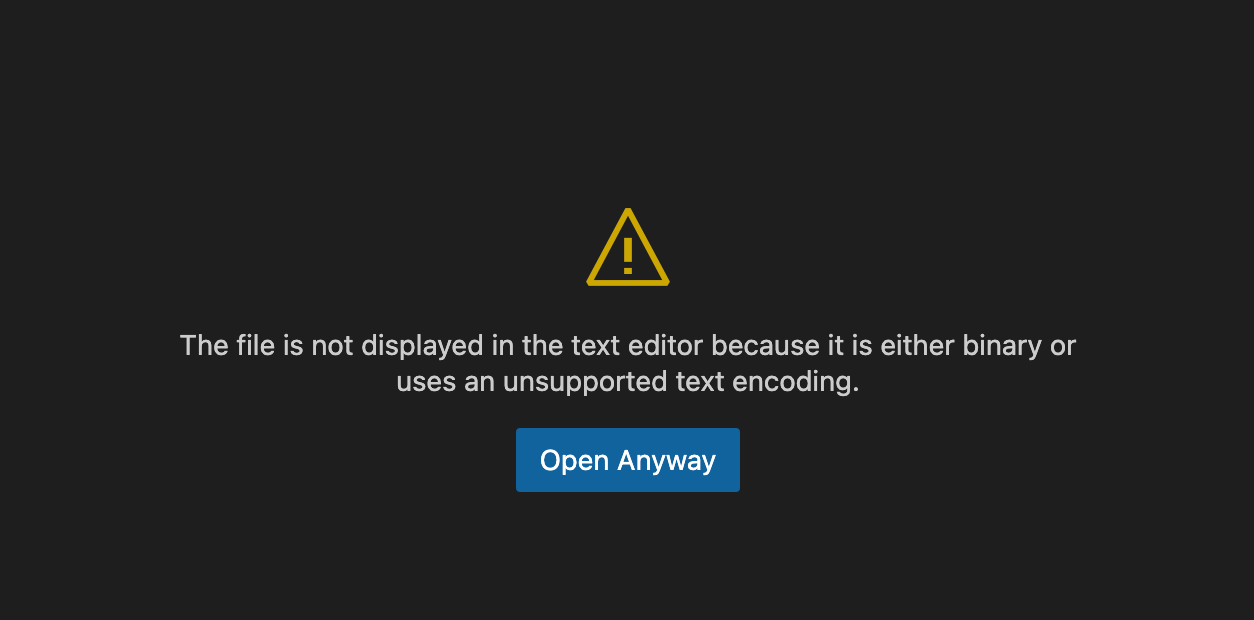
If you click on “Open Anyway”, you will see something like this:
which is not helpful. Luckily there are tools do decompress the file. My favorite command (a command line tool) is qpdf. The syntax for decompressing everything is
qpdf --qdf --object-streams=disable myfile.pdf uncompressed.pdf
Now the PDF looks much more friendly:
%PDF-1.6
%����
%QDF-1.0
%% Original object ID: 17 0
1 0 obj
<<
/Lang (en)
/PageMode /UseNone
/Pages 3 0 R
/Type /Catalog
>>
endobj
You can now see all the objects of the PDF file and see if there are any errors. Sometimes there are very subltle errors such as:
1 0 obj
<<
/Lang (en)
/PageMode UseNone
/Pages 3 0 R
/Type /Catalog
>>
endobj
Have you spotted the mistake? The name UseNone in line 4 is missing the / in front.
qpdf would have issued a warning in this case:
WARNING: publisher.pdf object stream 3 (object 17 0, offset 1157): unknown token while reading object; treating as string qpdf: operation succeeded with warnings; resulting file may have some problems
Other tools
But there are other tools to check the PDF:
pdfcpu
pdfcpu validate publisher.pdf
finds this error as well:
validating(mode=relaxed) publisher.pdf ... decodeObjectStreamObjects: problem decoding object stream 3 : strconv.ParseFloat: parsing "UseNone": invalid syntax
VeraPDF
VeraPDF comes in two flavors: a command line tool and the same with a graphical user interface.
VeraPDF is good to check against a certain PDF standard such as PDF/A-1, but for this simple case (a missing slash in front of UseNone) it failed to find the problem (but reported other problems, because the PDF is not A-1 compliant).
Adobe Acrobat
I don’t need to explain what Adobe Acrobat is. You can subscribe to it for currently 19.99 USD and is a very feature rich PDF editor. It also has the ability to do syntax checking and validating against PDF standards.
I the case of the missing slash (see above) this tool is not helpful:
Logic errors
If there is a logic problem in the file format, Acrobat is a bit more helpful. For example in a hyperlink, the object should look like this:
<<
/A <<
/S /URI
/Type /Action
/URI (https://www.speedata.de)
>>
/Border [ 0 0 0 ]
/Rect [ 28.346 801.543 107.326 813.543 ]
/Subtype /Link
/Type /Annot
>>
When you have a wong type (/Type /XAction for example), the syntax of the PDF file is correct, but the logical structure is incorrect.
Adobe Acrobat complains:
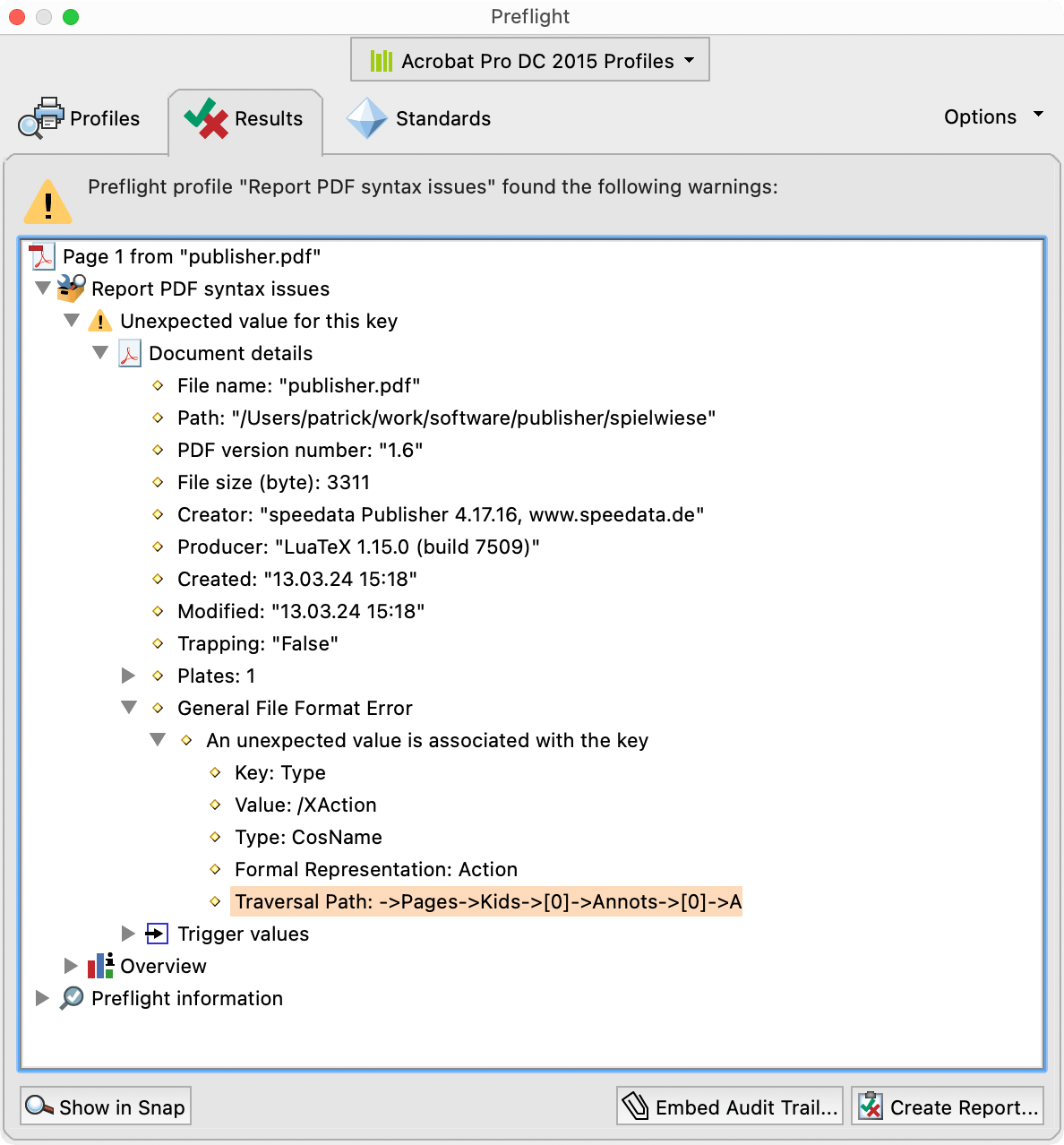
and shows exactly the problem location.
Also pdfcpu can find the logic error:
$ pdfcpu validate publisher.pdf
validating(mode=relaxed) publisher.pdf ...
validation error (obj#:8): pdfcpu: validateNameEntry:
dict=actionDict entry=Type invalid dict entry: XAction
Checking for conformance
Adobe Acrobat and veraPDF can check for conformance to some PDF standards.
While veraPDF only validates conforming to PDF/A (archiving) and PDF/UA (accessibility) standards, whereas Adobe Acrobat checks conforming to many other PDF standards such as PDF/X (graphics exchange).
There are two specialized validators to be mentioned: the PDF accessibility checker (Windows only) which test against PDF/UA compliance.
The ZUGFeRD validation portal validates against the electronic invoice standard used in the EU.
PDF 2.0
Although the PDF 2.0 standard is a few years old now, only very few validators can handle PDF 2.0. Currently only pdfcpu can validate PDF 2.0 files. It has a disclaimer that it has only limited PDF support yet.
Conclusion
Usually I use a variety of tools to validate my PDF files. First I decompress the file with qpdf, then look into the file with a text editor. If I can’t find an error while looking at the text, I open the file in Adobe Acrobat, and try to use the preflight tool with the “syntax check” profile. But using pdfcpu is also handy. veraPDF has the advantage that it mentions the source of the error next to a reference to the ISO standard which describes the correct way.
For special cases I use the PDF accessibility checker or the ZUGFeRD validation portal.