
What is PDF? Part 1 – the basics
Categories: Development
This will get very technical again and is for those of you who want to understand what a PDF file is.
This is part 1 of a mini-series on PDF. I’ll update this section when the next parts are finished.
Part 1 – PDF syntax and file structure
Part 2 – Fonts
Part 3 - Vector graphics
Part 4 - Interactive features
Part 5 - Metadata
Part 6 - Tagged PDF
Please note that all of these examples are created manually. If you wish to experiment with the examples, you can do so yourself. For more information, visit https://github.com/speedata/fixxref which provides a small program that supports manual PDF editing.
PDF syntax and file structure
All the examples will be in a repository on GitHub for download, as copying and pasting from this page may corrupt the code due to the significance of whitespace.
If you encounter an error, please see the previous post in this blog on how to debug the PDF.
Let’s dive in
This is a complete and valid PDF file, which I will explain later (get the source):
%PDF-1.6
%··
1 0 obj
<<
/Type /Catalog
/Pages 2 0 R
>>
endobj
2 0 obj
<<
/Type /Pages
/Kids [ 3 0 R ]
/Count 1
>>
endobj
3 0 obj
<<
/Type /Page
/MediaBox [ 0 0 200 200 ]
/Contents 4 0 R
/Parent 2 0 R
/Resources << >>
>>
endobj
4 0 obj
<<
/Length 23
>>
stream
2 w 10 10 180 180 re S
endstream
endobj
xref
0 5
0000000000 65535 f
0000000015 00000 n
0000000073 00000 n
0000000145 00000 n
0000000272 00000 n
trailer <<
/Size 5
/Root 1 0 R
>>
startxref
348
%%EOF
This looks structured, and you may be able to guess the meaning of some of the elements, even if you have never looked inside a PDF.
Basic file structure
The basic structure of a PDF file is as follows:

where the header in my example above is this:
%PDF-1.6
%··
and the XRef and trailer
xref
0 5
0000000000 65535 f
0000000015 00000 n
0000000073 00000 n
0000000145 00000 n
0000000272 00000 n
trailer <<
/Size 5
/Root 1 0 R
>>
startxref
348
%%EOF
Objects
And everything in between is an object, for example the Pages object (I capitalize object names with a special meaning, usually the name after the word /Type):
2 0 obj
<<
/Type /Pages
/Kids [ 3 0 R ]
/Count 1
>>
endobj
This is object number 2, a dictionary with three entries. There are several types of objects in PDF
| Type | Example |
|---|---|
| Boolean values | true, false |
| Integer and real numbers | 1, -3, 4. −.002 |
| Names | /Type, /Pages |
| Arrays | [ 1 2 3 ] |
| Dictionaries | « /Type /Pages /Count 1 » |
| Streams | beginstream … endstream |
| The null object | null |
| Strings | (a string) |
Objects can be direct objects, like the number 123, or indirect objects starting with a string similar to 3 0 obj as above. Each indirect object has a number.
There is another syntax feature in PDF: it can have comments. Anything following a % sign is treated as a comment. There are only two places in the PDF where the % signs have a meaning: the start of file marker and the %%EOF marker at the end of the PDF file.
The header
There are two leftovers, let me start with the easy one: the header. It consists of the form
%PDF major.minor
%four bytes > 127
The major.minor must be something like 1.7 or 2.0, and the four bytes > 127 are there to prevent the file from being recognized as a text file. If you use characters that are non-ASCII, but still common text characters, you can still view the PDF file in a text editor. This is why I use the middle dot (·) in my example. It is outside the ASCII range, but will still be displayed in most text editors.
The XRef section and the trailer
Now for the ugliest part of PDF. Each (indirect) object has a byte position within the PDF file. In my example above, the number 2 in 2 0 obj is exactly 75 bytes “away” from the beginning of the file. To find the objects in the PDF, there is a lookup table at the end of the PDF file that points to each indirect object.
The XRef table has an entry for each object. In front of each chunk there are two numbers, the object number of the first entry in the chunk and the number of entries in the chunk.
The first entry is special and must follow exactly the form shown. Each line must be exactly 20 bytes long, which means that after the n in a line there must be a whitespace character, 0000000019 00000 n .
After the XRef section, the trailer contains information about the root object (the Document object) and the number of objects in the PDF file.
After the trailer there must be the keyword startxref, the byte offset of the last XRef table (there can be more than one) and followed by %%EOF.
Multiple “views” on the PDF
There are multiple “views” of the PDF file. You can look at it from a syntax point of view, where the PDF file is a flat collection of (indirect) objects, each referenced from the XRef table.
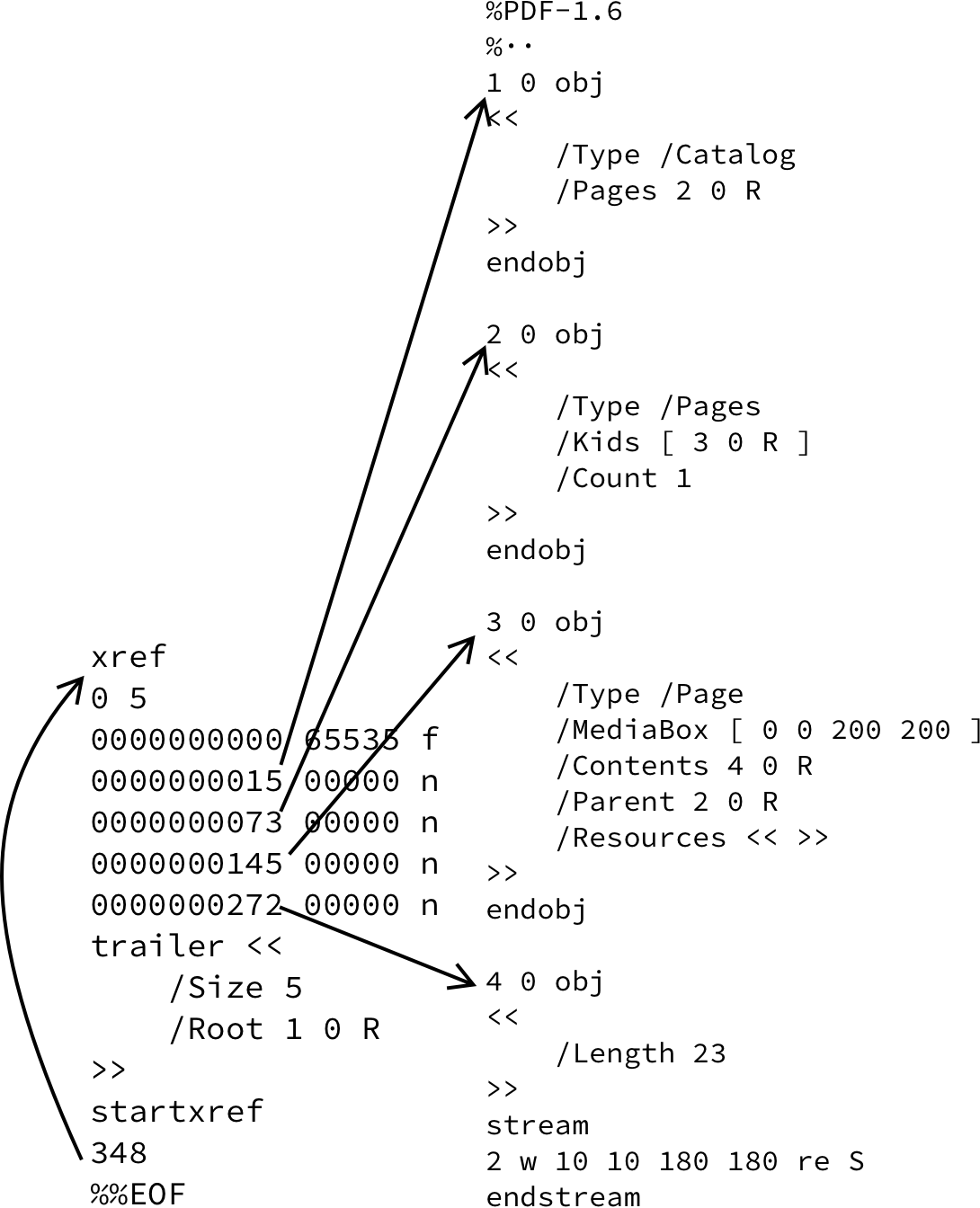
It is also possible to have a semantic view of the PDF. The PDF file is built into a tree-like data structure where the root node (the Document object) is referenced by the trailer. The Pages object contains a list of all pages, and each page has a back reference to the Pages object.
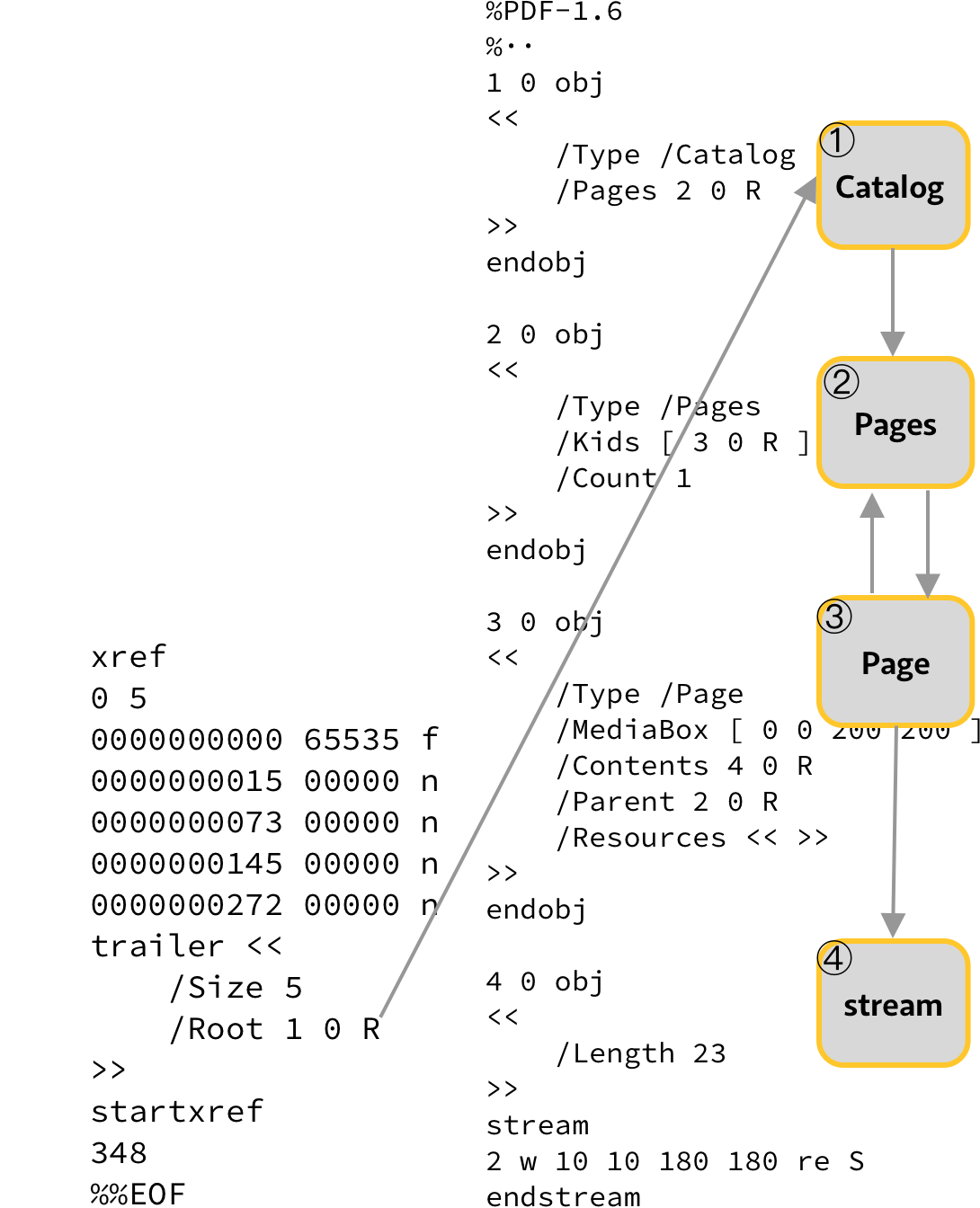
I don’t always tell the whole truth, that would only cause confusion. For example, there can be multiple Pages objects that can group Page objects.
Creating a PDF by hand
If you ever thought about creating a PDF file in your text editor: forget it.
Seriously, creating and maintaining the XRef table is hard. If you add a few bytes at the beginning of the file, you have to update every line in the XRef table. And you have to make sure that there is a space at the end of each line in the XRef table so that the entry is exactly 20 bytes long.
I have created a simple utility for this purpose. You can write objects in the PDF file and it will update the trailer. fixxref (the name of the software) also updates the /Length entries in stream objects (object 4 in my PDF). The /Length entry contains the number of bytes between the stream and endstream keywords.
I use Visual Studio Code to edit PDFs, which has a nice PDF mode. You can click on any object reference or entry in the XRef table and jump to the beginning of the object. It also provides syntax highlighting.
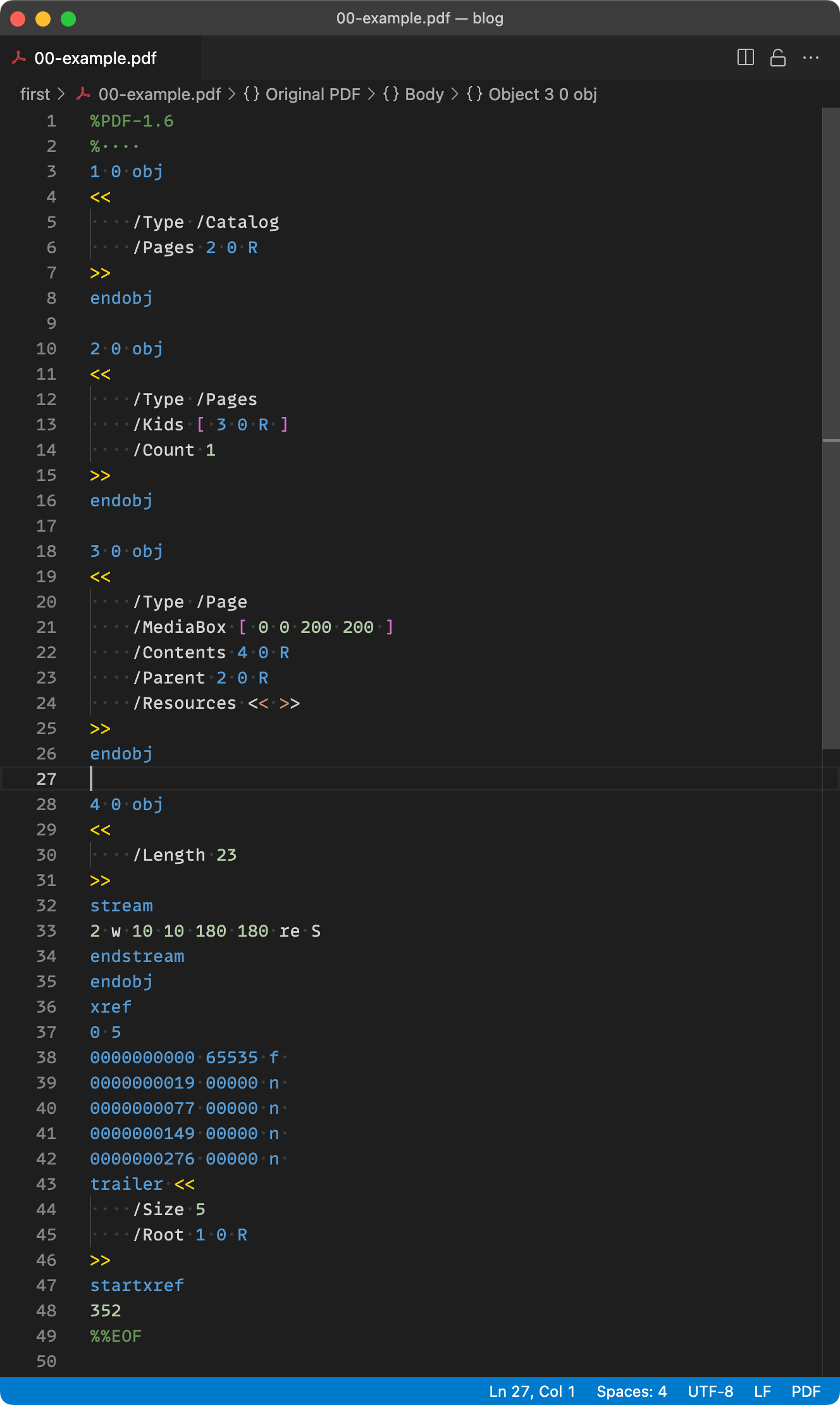
To automate XRef fixing with fixxref, I installed a “Run on Save” extension that runs fixxref every time the PDF file is saved. My configuration is
{
"emeraldwalk.runonsave": {
"commands": [
{
"match": "\\.pdf$",
"cmd": "fixxref ${file}",
}
]
}
}
Which is saved in .vscode/settings.json of the working directory (so it does not affect any other PDF files).
Stay tuned for next week’s episode of “Inside PDF”….