
What is PDF? Part 5 - Metadata
Categories: Development

This part of the mini-series on PDF will be about metadata. Metadata is not visible in the document when printed, but only useful for curious human beings and some software that needs a PDF in a special format (like electronic invoices in the ZUGFeRD format). Metadata is always “about this document”, so it changes from document to document and must be applied individually.
This is part 5 of a mini-series on PDF.
Part 1 – PDF syntax and file structure
Part 2 – Fonts
Part 3 - Vector graphics
Part 4 - Interactive features
Part 5 - Metadata
Please note that all of these examples are created manually. If you wish to experiment with the examples, you can do so yourself. For more information, visit https://github.com/speedata/fixxref which provides a small program that supports manual PDF editing.
Info-dict
The classic way of providing metadata is the info dictionary. It is referenced from the document trailer dictionary and contains all basic data about the document’s author, title and so forth:
2 0 obj
<<
/Author (Patrick Gundlach)
/Title (A sample document)
/Subject (How to create a metadata dictionary)
/Keywords (metadata,pdf,info dict)
/Creator (Manual editing)
/Producer (fixxref)
/CreationDate (D:20240418133619+02'00')
>>
endobj
and the trailer of the document is
trailer <<
/Size 6
/Root 1 0 R
/Info 2 0 R
>>
startxref
617
%%EOF
The complete document can be found online, as always.
To show the data, you can use pdfinfo on the command line (part of poppler):
$ pdfinfo 05-infodict.pdf
Title: A sample document
Subject: How to create a metadata dictionary
Keywords: metadata,pdf,info dict
Author: Patrick Gundlach
Creator: Manual editing
Producer: fixxref
CreationDate: Thu Apr 18 13:36:19 2024 CEST
Custom Metadata: no
Metadata Stream: no
Tagged: no
UserProperties: no
Suspects: no
Form: none
JavaScript: no
Pages: 1
Encrypted: no
Page size: 200 x 200 pts
Page rot: 0
File size: 827 bytes
Optimized: no
PDF version: 1.7
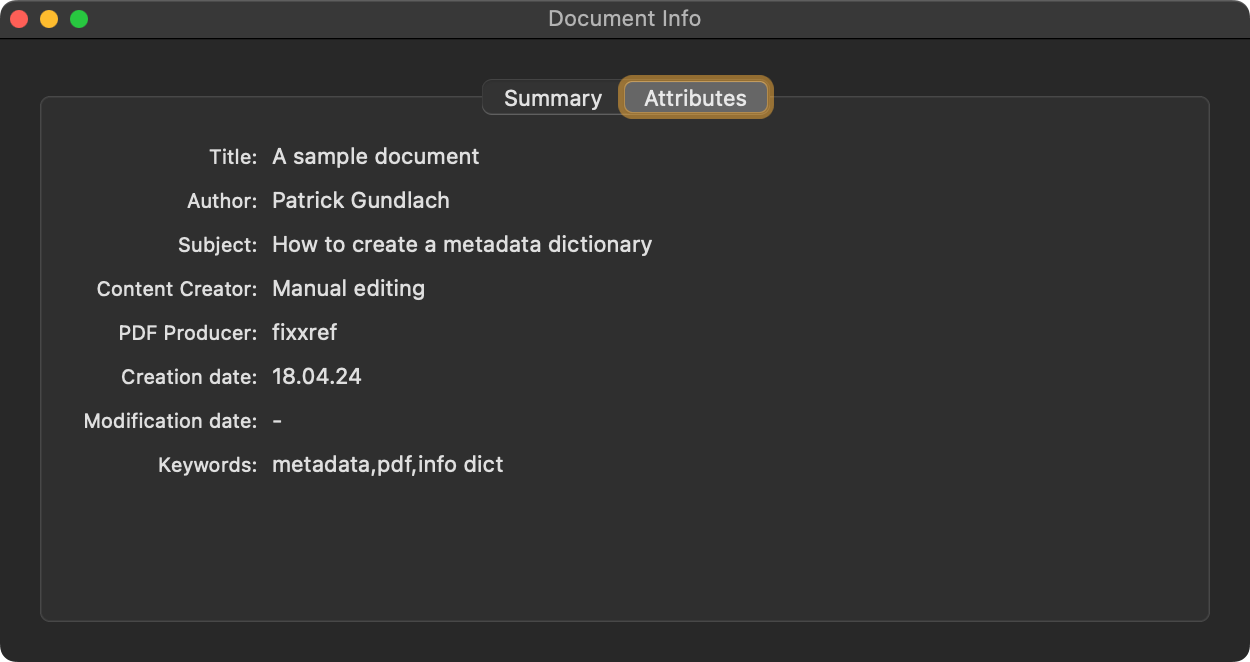
Any PDF viewer application should show the metadata similar to Skim (macOS):
XML Metadata
Starting with PDF 2.0, the info dictionary is deprecated and replaced by XML based metadata. This XML is referenced from the Document dictionary:
1 0 obj
<<
/Type /Catalog
/Pages 3 0 R
/Metadata 2 0 R
>>
endobj
and the structure of the metadata itself looks like:
2 0 obj
<<
/Length 12345
/Type/Metadata
/Subtype/XML
>>
stream
<?xpacket begin="�" id="W5M0MpCehiHzreSzNTczkc9d"?>
<x:xmpmeta xmlns:x="adobe:ns:meta/">
...
</x:xmpmeta>
<?xpacket end="w"?>
endstream
endobj
Don’t ask me why it looks like this. The character at begin=“�” is the UTF-8 sequence 0xEFBBBF (239, 187, 191 decimal) representing the Unicode code point U+FEFF ZERO WIDTH NO-BREAK SPACE.
The XMP standard is described in three parts and can be found online at www.adobe.com/devnet/xmp.html.
The contents of the metadata is also XML, using information and standards of various formats, for example RDF and Dublin Core.
To me it is not always clear when to use which metadata to use. For example there are multiple ways to specify the keywords in metadata:
<pdf:Keywords>metadata,pdf,info dict</pdf:Keywords>
or
<dc:subject>
<rdf:Bag>
<rdf:li>metadata</rdf:li>
<rdf:li>pdf</rdf:li>
<rdf:li>info dict</rdf:li>
</rdf:Bag>
</dc:subject>
Some viewers complain when only the first variant is present, so there is a bit of experimenting with the supported XML types.
Note that the metadata stream must not be compressed.
The complete metadata stream representing the info dict from above looks like this:
2 0 obj
<<
/Length 1715
/Type/Metadata
/Subtype/XML
>>
stream
<?xpacket begin="" id="W5M0MpCehiHzreSzNTczkc9d"?>
<x:xmpmeta xmlns:x="adobe:ns:meta/">
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about=""
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:xmp="http://ns.adobe.com/xap/1.0/"
xmlns:pdf="http://ns.adobe.com/pdf/1.3/"
xmlns:xmpMM="http://ns.adobe.com/xap/1.0/mm/">
<dc:format>application/pdf</dc:format>
<dc:creator>
<rdf:Seq>
<rdf:li>Patrick Gundlach</rdf:li>
</rdf:Seq>
</dc:creator>
<dc:description>
<rdf:Alt>
<rdf:li xml:lang="x-default">How to create a metadata dictionary</rdf:li>
</rdf:Alt>
</dc:description>
<dc:title>
<rdf:Alt>
<rdf:li xml:lang="x-default">A sample document</rdf:li>
</rdf:Alt>
</dc:title>
<dc:subject>
<rdf:Bag>
<rdf:li>metadata</rdf:li>
<rdf:li>pdf</rdf:li>
<rdf:li>info dict</rdf:li>
</rdf:Bag>
</dc:subject>
<xmp:CreateDate>2024-04-18T13:36:19+02:00</xmp:CreateDate>
<xmp:CreatorTool>Manual editing</xmp:CreatorTool>
<xmp:ModifyDate>2024-04-22T14:09:12+02:00</xmp:ModifyDate>
<xmp:MetadataDate>2024-04-22T14:09:12+02:00</xmp:MetadataDate>
<pdf:Producer>fixxref</pdf:Producer>
<xmpMM:DocumentID>uuid:279dccf9-fbb4-c743-b847-5210c26ff4fc</xmpMM:DocumentID>
<xmpMM:InstanceID>uuid:8bc9f1fd-b3e9-724b-b317-1a165fa57303</xmpMM:InstanceID>
</rdf:Description>
</rdf:RDF>
</x:xmpmeta>
<?xpacket end="w"?>
endstream
endobj
The complete PDF file can be downloaded from the examples repository.